class: center, middle, inverse, title-slide # Getting Started with R ### R for the Rest of Us --- layout: true <div class="dk-footer"> <span> <a href="https://rfortherestofus.com/" target="_blank">R for the Rest of Us </a> </span> </div> --- class: center, middle, dk-section-title background-image: url("images/installation.jpeg") # Installation --- ## Install R The first thing you need to do is download the R software. Go to the [Comprehensive R Archive Network (aka “CRAN”) website](https://cran.r-project.org/) and download the software for your operating system (Windows, Mac, or Linux). 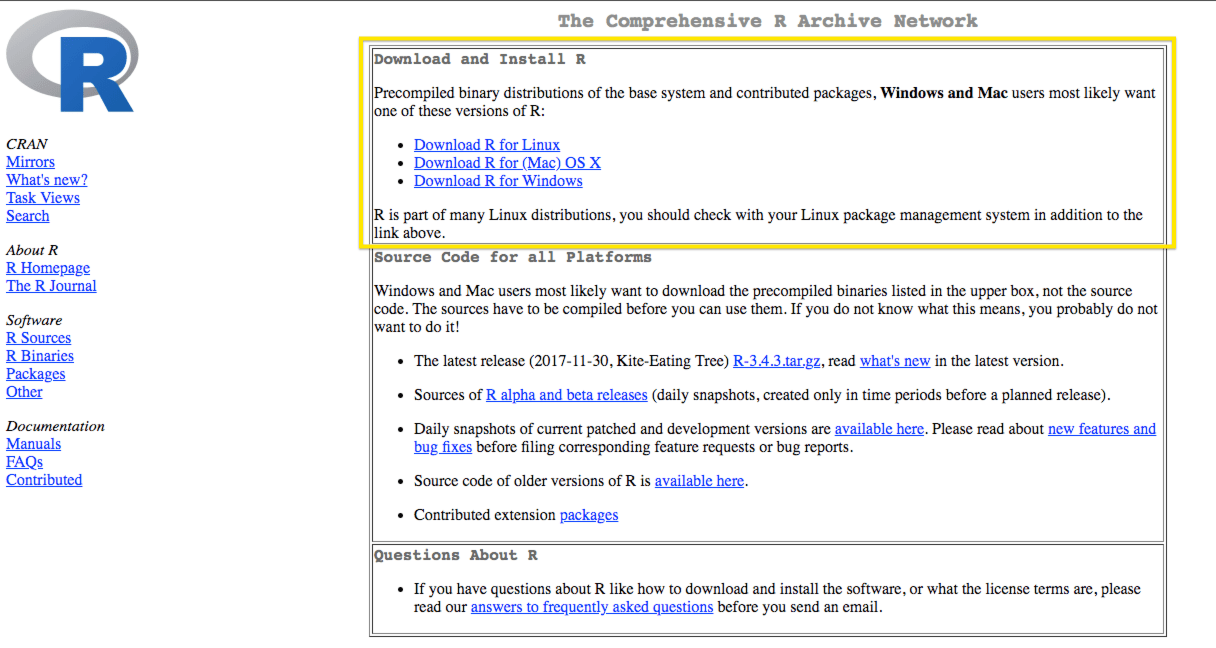 --- ### Working Directly in R  --- ### Working Directly in R 1. Enter: 2 + 2 2. Hit return 3. View result --- class:inverse ### Your Turn 1. Download and Install R -- 1. Open R -- 1. Use any mathematical operators (+, -, /, and *) to create an expression and make sure it works as expected --- ## RStudio -- .center[  .small[Courtesy [Modern Dive](http://moderndive.com/2-getting-started.html#what-are-r-and-rstudio)] ] --- ### RStudio If you use RStudio, you’ll have a graphical user interface, the ability to see all of your stored information, and much more. 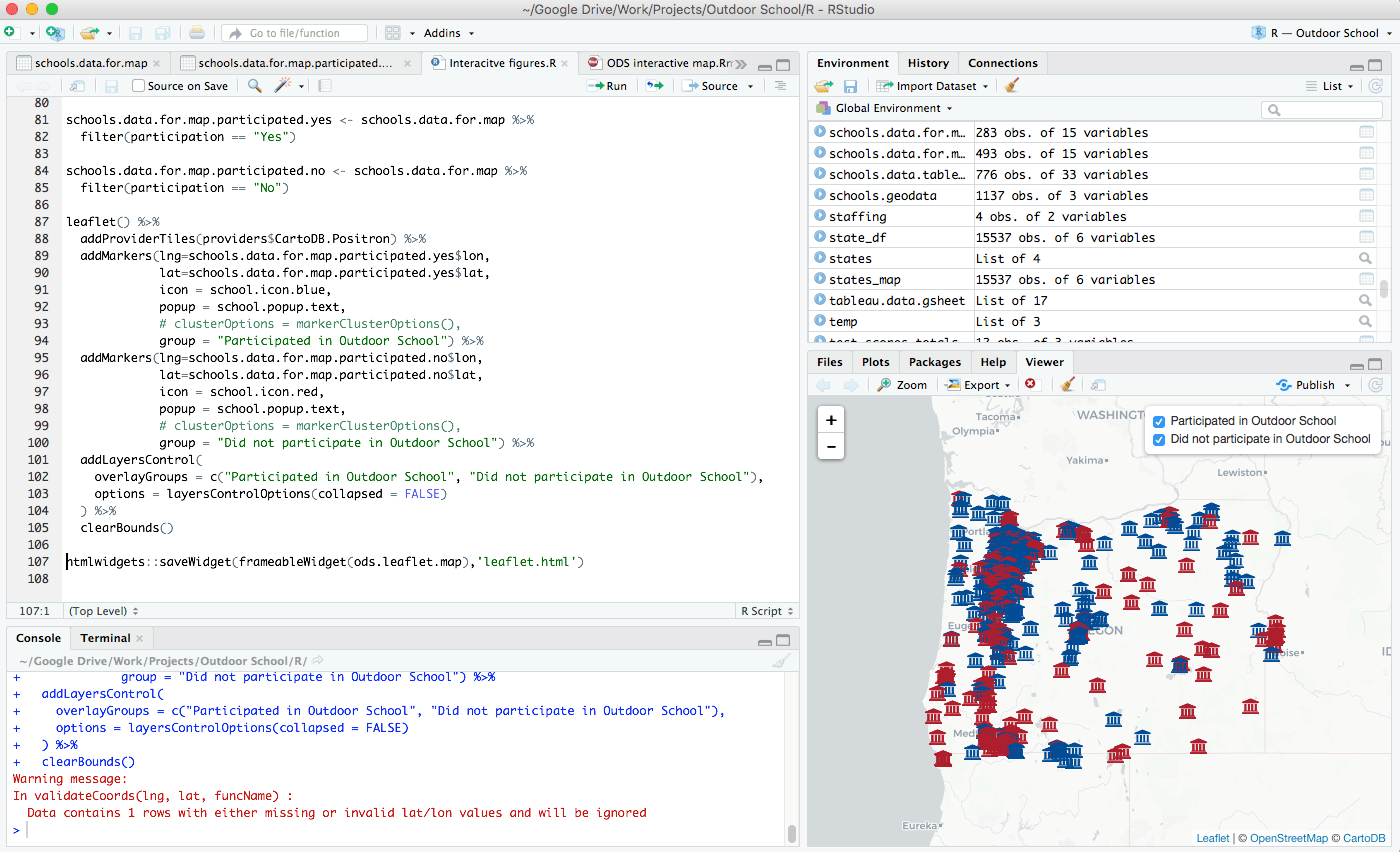 --- ### Download RStudio Download RStudio at the [RStudio website](https://www.rstudio.com/products/rstudio/download/#download). Ignore the various versions listed there. All you need is the latest version of RStudio Desktop. 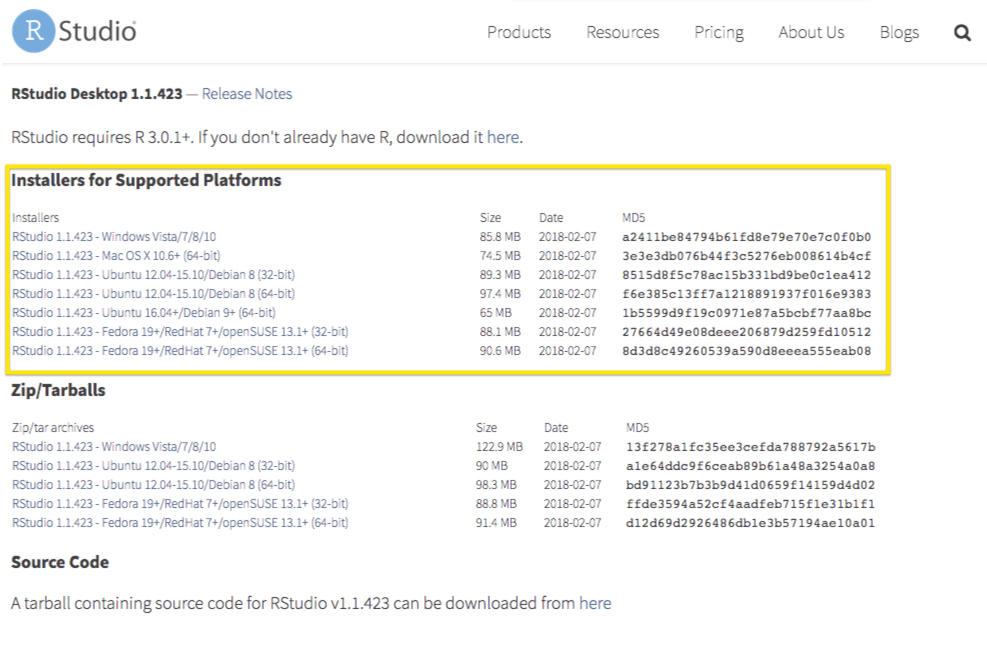 --- ### Tour of RStudio .center[  ] --- class:inverse ### Your Turn 1. Download and Install RStudio -- 1. Open RStudio -- 1. Working in the console pane, use any mathematical operators (+, -, /, and *) to create an expression and make sure it works as expected --- class: center, middle, dk-section-title background-image: url("images/projects.jpeg") # Projects --- ## Projects -- Projects allow you to keep a collection of files all together, including: -- - R scripts -- - RMarkdown files (more on those soon) -- - Data files -- - And much more! --- ### Sample Project .center[  ] --- ### How to Create a Project 1. File -> New Project -- 2. Quit RStudio, Double-click .Rproj file to reopen project --- class:inverse ### Your Turn 1. Create a new project (doesn't matter if it's in a new or existing directory) -- 2. Quit RStudio, double-click the .Rproj file and reopen your project --- class: center, middle, dk-section-title background-image: url("images/download-course-project.jpeg") # Download Course Project --- class: inverse ## Your Turn -- Enter the following into the RStudio console pane: ```r install.packages("usethis") library(usethis) use_course("http://bit.ly/getting-started-with-r") ``` ??? You'll now have a copy of the project created for this course that we'll use from here on out --- class: center, middle, dk-section-title background-image: url("images/files.jpg") opacity: 0.5 # Files in R --- ## File Types There are **two main file types** that you'll work with: .pull-left[ **R scripts (.R)** Text is assumed to be executable R code unless you comment it (more on this soon) ```r # This is a comment data <- read_csv("data.csv") ``` ] -- .pull-right[ **RMarkdown files (.Rmd)** Text is assumed to be text unless you put it in a code chunk (more on this soon)  ] --- ## R Scripts Create new script file: File -> New File -> R Script  --- ## How to Run Code Run the code: control + enter on Windows, command + enter on Mac keystrokes or use Run button  ??? Note that you don't have to highlight code. You can just hit run anywhere on line to run code. --- ## Comments Do them for others, and for your future self. ```r # This is a comment head(data, n = 5) ``` --- class: center, middle, dk-section-title background-image: url("images/packages.jpg") # Packages --- ## Packages Packages add functionality that is not present in base R. They're where much of the power of R is found. -- .center[  .small[Courtesy [Modern Dive](http://moderndive.com/2-getting-started.html#packages)] ] --- ## Packages We'll Use .pull-left[ .center[  ] ] .pull-right[ ### `tidyverse` The [`tidyverse`](https://tidyverse.org/) is a collection of packages. We'll use [`readr`](https://readr.tidyverse.org/) to import data. ] --- ## Packages We'll Use .pull-left[ ### `skimr` [`skimr`](https://github.com/ropensci/skimr) provides easy summary statistics. ] .pull-right[ .center[  ] ] --- ## Install Packages The syntax to install packages is as follows. ```r install.packages("tidyverse") install.packages("skimr") ``` The package name must be in quotes. -- .dk-highlight-box[ Packages should be installed **once per computer** (i.e. once you've installed a package, you don't need to do it again on the same computer). ] --- ## Load Packages To load packages, use the following syntax: ```r library(tidyverse) library(skimr) ``` Package names don't need to be quoted here (though they can be). -- .dk-highlight-box[ Packages should be loaded **once per session** (i.e. every time you start working in R, you need to load any packages you want to use). ] --- class:inverse ## Your Turn 1. Open the project you downloaded before (it should be on your desktop) -- 1. Open the exercises.R file -- 1. Install the tidyverse and skimr packages using the install.packages function -- 1. Load the tidyverse and skimr packages using the library function --- class: center, middle, dk-section-title background-image: url("images/data.jpg") # Import Data --- ## Import Data Let's read data from a CSV file. ```r faketucky <- read_csv("data/faketucky.csv") ``` We now have a data frame/tibble called `faketucky` that we can work with in R. ??? - Tibbles are ["modern data frames"](https://cran.r-project.org/web/packages/tibble/vignettes/tibble.html). The main difference for our purposes is that tibbles print much more nicely within R. - We'll use the terms tibble and data frame interchangeably. - For Excel files, try `read_excel` from the `readxl` package. - For SPSS files, try `read_sav` from the `haven` package. --- ## R is Case Sensitive R is **case sensitive** so choose one of the following for all objects and **be consistent**. .pull-left[ **Option** snake_case camelCase periods.in.names ] -- .pull-right[ **Example** student_data studentData student.data ] --- ## Directories If the data file is in the working directory, you only need to specify its name. ```r faketucky <- read_csv("faketucky.csv") ``` -- If the data file is not in the working directory, you need to specify full path name. -- When specifying the path name use of forward slash (“/”) not backslash (“\”). ```r faketucky <- read_csv("data/faketucky.csv") ``` --- ## Where Does our Data Live? Data we have imported is available in the environment/history pane. .center[  ] --- class:inverse ## Your Turn 1. Open the exercises.R file -- 1. Import the faketucky data into a data frame called `faketucky`. -- 1. Make sure you see `faketucky` in your environment/history pane. --- class: center, middle, dk-section-title background-image: url("images/function.jpg") # Objects and Functions --- ## Objects and Functions -- > To understand computations in R, two slogans are helpful: -- > Everything that exists is an **object**, and -- > Everything that happens is a **function** call. -- John Chambers, quoted in [Hadley Wickham's Advanced R](http://adv-r.had.co.nz/Functions.html). --- ## Objects and Functions .center[] --- ## Assignment Operator .center[  ] -- We assign the result of the `read_csv` **function** to the `faketucky` **object** --- class: center, middle, dk-section-title background-image: url("images/glasses.jpeg") # Examine Our Data --- ## Examine Our Data There are many ways to look at our data. We'll talk about a few. --- ## `faketucky` If you type the name of your data frame (i.e. `faketucky`), R will output the following: ```r faketucky ``` -- ``` ## # A tibble: 57,855 x 12 ## student_id first_high_scho… school_district male race_ethnicity ## <dbl> <chr> <chr> <dbl> <chr> ## 1 1622 Jackson Jackson 1 Multiple/Nati… ## 2 1877 Jackson Jackson 1 White ## 3 1941 Jackson Jackson 1 White ## 4 3442 Jackson Jackson 0 White ## 5 4623 Jackson Jackson 1 White ## 6 4913 Jackson Jackson 1 White ## 7 5754 Jackson Jackson 1 White ## 8 6293 Jackson Jackson 0 White ## 9 7010 Jackson Jackson 1 White ## 10 8343 Jackson Jackson 1 White ## # … with 57,845 more rows, and 7 more variables: free_and_reduced_lunch <dbl>, ## # percent_absent <dbl>, gpa <dbl>, act_reading_score <dbl>, ## # act_math_score <dbl>, received_high_school_diploma <dbl>, ## # enrolled_in_college <dbl> ``` --- ## `head` `head` shows us the first X rows. ```r head(faketucky, 5) ``` -- ``` ## # A tibble: 5 x 12 ## student_id first_high_scho… school_district male race_ethnicity ## <dbl> <chr> <chr> <dbl> <chr> ## 1 1622 Jackson Jackson 1 Multiple/Nati… ## 2 1877 Jackson Jackson 1 White ## 3 1941 Jackson Jackson 1 White ## 4 3442 Jackson Jackson 0 White ## 5 4623 Jackson Jackson 1 White ## # … with 7 more variables: free_and_reduced_lunch <dbl>, percent_absent <dbl>, ## # gpa <dbl>, act_reading_score <dbl>, act_math_score <dbl>, ## # received_high_school_diploma <dbl>, enrolled_in_college <dbl> ``` --- ## `head` ```r head(faketucky, 5) ``` -- .dk-highlight-box[ `faketucky` and the number 5 here are **arguments**. ] --- ## `tail` `tail` shows us the last X rows. ```r tail(faketucky, 5) ``` -- ``` ## # A tibble: 5 x 12 ## student_id first_high_scho… school_district male race_ethnicity ## <dbl> <chr> <chr> <dbl> <chr> ## 1 89364 Lookout Point Lookout Point 1 Hispanic ## 2 94764 Lookout Point Lookout Point 0 White ## 3 97538 Lookout Point Lookout Point 1 White ## 4 101342 Lookout Point Lookout Point 1 White ## 5 104903 Lookout Point Lookout Point 1 Hispanic ## # … with 7 more variables: free_and_reduced_lunch <dbl>, percent_absent <dbl>, ## # gpa <dbl>, act_reading_score <dbl>, act_math_score <dbl>, ## # received_high_school_diploma <dbl>, enrolled_in_college <dbl> ``` --- ## `View` `View` (note capital V) opens the RStudio viewer (or click on a data frame in the environment pane). ```r View(faketucky) ``` --- ## `skimr` The skimr package provides more detailed information about our data frame. It is also broken up by the type of variable. ```r skim(faketucky) ``` -- <table style='width: auto;' class='table table-condensed'> <caption>Data summary</caption> <thead> <tr> <th style="text-align:left;"> </th> <th style="text-align:left;"> </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> Name </td> <td style="text-align:left;"> faketucky </td> </tr> <tr> <td style="text-align:left;"> Number of rows </td> <td style="text-align:left;"> 57855 </td> </tr> <tr> <td style="text-align:left;"> Number of columns </td> <td style="text-align:left;"> 12 </td> </tr> <tr> <td style="text-align:left;"> _______________________ </td> <td style="text-align:left;"> </td> </tr> <tr> <td style="text-align:left;"> Column type frequency: </td> <td style="text-align:left;"> </td> </tr> <tr> <td style="text-align:left;"> character </td> <td style="text-align:left;"> 3 </td> </tr> <tr> <td style="text-align:left;"> numeric </td> <td style="text-align:left;"> 9 </td> </tr> <tr> <td style="text-align:left;"> ________________________ </td> <td style="text-align:left;"> </td> </tr> <tr> <td style="text-align:left;"> Group variables </td> <td style="text-align:left;"> </td> </tr> </tbody> </table> **Variable type: character** <table> <thead> <tr> <th style="text-align:left;"> skim_variable </th> <th style="text-align:right;"> n_missing </th> <th style="text-align:right;"> complete_rate </th> <th style="text-align:right;"> min </th> <th style="text-align:right;"> max </th> <th style="text-align:right;"> empty </th> <th style="text-align:right;"> n_unique </th> <th style="text-align:right;"> whitespace </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> first_high_school_attended </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1.00 </td> <td style="text-align:right;"> 4 </td> <td style="text-align:right;"> 14 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 393 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> school_district </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1.00 </td> <td style="text-align:right;"> 4 </td> <td style="text-align:right;"> 13 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 171 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> race_ethnicity </td> <td style="text-align:right;"> 794 </td> <td style="text-align:right;"> 0.99 </td> <td style="text-align:right;"> 5 </td> <td style="text-align:right;"> 24 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 5 </td> <td style="text-align:right;"> 0 </td> </tr> </tbody> </table> **Variable type: numeric** <table> <thead> <tr> <th style="text-align:left;"> skim_variable </th> <th style="text-align:right;"> n_missing </th> <th style="text-align:right;"> complete_rate </th> <th style="text-align:right;"> mean </th> <th style="text-align:right;"> sd </th> <th style="text-align:right;"> p0 </th> <th style="text-align:right;"> p25 </th> <th style="text-align:right;"> p50 </th> <th style="text-align:right;"> p75 </th> <th style="text-align:right;"> p100 </th> <th style="text-align:left;"> hist </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> student_id </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 55922.15 </td> <td style="text-align:right;"> 32332.71 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 27909.50 </td> <td style="text-align:right;"> 56070.00 </td> <td style="text-align:right;"> 83872.50 </td> <td style="text-align:right;"> 111990 </td> <td style="text-align:left;"> ▇▇▇▇▇ </td> </tr> <tr> <td style="text-align:left;"> male </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0.76 </td> <td style="text-align:right;"> 15.54 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0.00 </td> <td style="text-align:right;"> 1.00 </td> <td style="text-align:right;"> 1.00 </td> <td style="text-align:right;"> 999 </td> <td style="text-align:left;"> ▇▁▁▁▁ </td> </tr> <tr> <td style="text-align:left;"> free_and_reduced_lunch </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 15.45 </td> <td style="text-align:right;"> 120.82 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0.00 </td> <td style="text-align:right;"> 1.00 </td> <td style="text-align:right;"> 1.00 </td> <td style="text-align:right;"> 999 </td> <td style="text-align:left;"> ▇▁▁▁▁ </td> </tr> <tr> <td style="text-align:left;"> percent_absent </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 10.68 </td> <td style="text-align:right;"> 46.19 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 3.27 </td> <td style="text-align:right;"> 6.28 </td> <td style="text-align:right;"> 11.35 </td> <td style="text-align:right;"> 3153 </td> <td style="text-align:left;"> ▇▁▁▁▁ </td> </tr> <tr> <td style="text-align:left;"> gpa </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 40.22 </td> <td style="text-align:right;"> 189.95 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 2.02 </td> <td style="text-align:right;"> 2.70 </td> <td style="text-align:right;"> 3.36 </td> <td style="text-align:right;"> 999 </td> <td style="text-align:left;"> ▇▁▁▁▁ </td> </tr> <tr> <td style="text-align:left;"> act_reading_score </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 258.78 </td> <td style="text-align:right;"> 420.65 </td> <td style="text-align:right;"> 2 </td> <td style="text-align:right;"> 16.00 </td> <td style="text-align:right;"> 22.00 </td> <td style="text-align:right;"> 34.00 </td> <td style="text-align:right;"> 999 </td> <td style="text-align:left;"> ▇▁▁▁▂ </td> </tr> <tr> <td style="text-align:left;"> act_math_score </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 257.85 </td> <td style="text-align:right;"> 420.77 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 16.00 </td> <td style="text-align:right;"> 20.00 </td> <td style="text-align:right;"> 33.00 </td> <td style="text-align:right;"> 999 </td> <td style="text-align:left;"> ▇▁▁▁▂ </td> </tr> <tr> <td style="text-align:left;"> received_high_school_diploma </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0.74 </td> <td style="text-align:right;"> 0.44 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0.00 </td> <td style="text-align:right;"> 1.00 </td> <td style="text-align:right;"> 1.00 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:left;"> ▃▁▁▁▇ </td> </tr> <tr> <td style="text-align:left;"> enrolled_in_college </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 255.74 </td> <td style="text-align:right;"> 435.54 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0.00 </td> <td style="text-align:right;"> 1.00 </td> <td style="text-align:right;"> 999.00 </td> <td style="text-align:right;"> 999 </td> <td style="text-align:left;"> ▇▁▁▁▃ </td> </tr> </tbody> </table> --- class:inverse ## Your Turn 1. Open the file exercises.R -- 1. Follow the instructions to use the `head()`, `tail()`, `View()`, and `skim()` functions to examine your data. --- class: center, middle, dk-section-title background-image: url("images/issues.jpeg") # We've Got Issues! --- ## We've Got Issues! Several variables have max values of 999. This seems suspicious!  --- ## We've Got Issues! Several variables show up as numeric, but we know they're **not actually numeric**.  --- ## Let's Import Our Data Again We need to do two things: -- 1. Tell `read_csv` how to handle **missing data** -- 1. Make sure `read_csv` assigns the correct **data type** to each variable --- ## Missing Data Here's how we imported our data the first time: ```r faketucky <- read_csv("data/faketucky.csv") ``` -- To tell R which data is missing, simply add an argument to the `read_csv` function as follows: ```r faketucky <- read_csv("data/faketucky.csv", * na = "999") ``` --- ## Missing Data If we skim our data again, we'll see that there are no longer 999 values. ```r skim(faketucky) ``` ??? Do this in R --- ## Data Types When you run `read_csv` you'll see the following message, which tells you the data types that have been assigned to your data frame. -- ```r Parsed with column specification: cols( student_id = col_double(), first_high_school_attended = col_character(), school_district = col_character(), male = col_double(), race_ethnicity = col_character(), free_and_reduced_lunch = col_double(), percent_absent = col_double(), gpa = col_double(), act_reading_score = col_double(), act_math_score = col_double(), received_high_school_diploma = col_double(), enrolled_in_college = col_double() ) ``` --- ## Data Types - **Double/Numeric** (e.g. 2.5) -- - **Character** (e.g. "Male") .small[There are [many other data types in R](https://www.statmethods.net/input/datatypes.html) that we won't discuss in this course. ] --- ## Data Types ```r faketucky <- read_csv("data/faketucky.csv", na = "999", * col_types = list(enrolled_in_college = col_character(), * free_and_reduced_lunch = col_character(), * male = col_character(), * received_high_school_diploma = col_character())) ``` --- class:inverse ## Your Turn 1. Open the file exercises.R and change the code so that you correctly import the `faketucky` data frame, telling `read_csv` which data is missing and explictly defining column types where necessary. -- 1. After you make changes to how you import your data, rerun the code in the Examine Data section to make sure everything worked! --- class: center, middle, dk-section-title background-image: url("images/help.jpeg") # Getting Help --- ### ?function Use the ? to get help about anything you're confused about ```r ?read_csv ``` --- ## Tidyverse Website [](https://www.tidyverse.org/) --- ## Package Vignettes [](https://cran.r-project.org/web/packages/skimr/vignettes/Using_skimr.html) --- ## Twitter [](https://twitter.com/search?q=%23rstats) --- ## R for Data Science Community [](https://www.rfordatasci.com/) --- ## Google [](https://twitter.com/ekaleedmiston/status/1081221822186696706)